
By Minshuo Chen
Background and Motivation
Deep learning has made significant breakthroughs in various real-world applications, such as computer vision, natural language processing, healthcare, robotics, etc. In image classification, the winner of the 
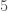

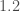

The empirical success of deep learning is, however, not well explained by existing theories [2, 3]. Existing results suggest that, to achieve an 
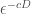


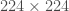
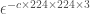

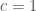

To bridge the aforementioned gap between theory and practice, we take the low-dimensional geometric structures of data into consideration. This is motivated by the fact that in real-world applications, high-dimensional data often depend on a small number of intrinsic parameters.
In Figure 1, the left panel shows images of the same teapot obtained under rotations, where the intrinsic parameter is the angle of the rotation; The right panel shows the Yale Face dataset where the intrinsic parameters are the poses of the faces. These images are stored as large-size matrices, but each one only depends on one or two intrinsic parameters. It is, therefore, reasonable to assume that data are in 
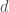
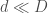

Figure 1. Left panel: images of the same teapot obtained under rotations [4]. Right panel: face images with different poses in Yale Face dataset [5].
Efficient Statistical Recovery
Our research focuses on learning a regression model. Assume that 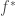


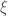
Can we gain benefits by exploiting low-dimensional geometric structures of data, when learning regression models using deep neural networks?
Our theory provides a positive answer by establishing an efficient statistical recovery theory with a sample complexity depending on the intrinsic data dimension
Main Result [6]: Suppose 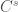
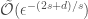
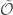
- the sample complexity depends on the intrinsic dimension
;
- we consider the rectified linear unit (ReLU) activation, since it is commonly used in deep networks, and eases the notorious vanishing gradient problem [7];
- our result demonstrates that neural networks are adaptive to low-dimensional geometric structures of data, which partially explains the power of neural networks in learning real-world data with structures.
Key Ingredients in Our Analysis
A natural question: How is the network architecture properly designed? At a coarse level, it crucially depends on
- the smoothness of
- the curvature of the manifold: highly curved manifold may skyrocket the difficulty of the approximation (see the bottom row of Figure 2).

Figure 2. Upper row: easier approximations for smoother functions on the same manifold. Bottom row: easier approximations for functions on a flatter manifold.
An Efficient Approximation Theory
Existing theories of neural networks [8, 9] show that, to approximate 
 Figure 3. Network size for the ImageNet dataset [10]. Existing theories suggest a huge number of parameters to achieve a desired accuracy.
Figure 3. Network size for the ImageNet dataset [10]. Existing theories suggest a huge number of parameters to achieve a desired accuracy.
We exploit the low-dimensional geometric structures to bridge such a gap, by establishing an efficient approximation theory for functions on low-dimensional manifolds using deep neural networks. To approximate 

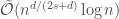


If you are interested in reading more about nonparametric regression using deep neural networks on low dimensional manifolds, please refer to our full-paper.
About the Authors
This research is joint work by Minshuo Chen, Haoming Jiang, Wenjing Liao, and Tuo Zhao. Minshuo Chen and Haoming Jiang are third year Ph.D. students in Machine Learning at Georgia Tech advised by Prof. Tuo Zhao. Minshuo Chen’s research focuses on developing principled methodologies and theoretical foundations of deep learning.
References
[1] Hu, Jie, Li Shen, and Gang Sun. “Squeeze-and-excitation networks.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2018.
[2] Györfi, László, Kohler, Michael, Krzyzak, Adam, and Walk, Harro. “A distribution-free theory of nonparametric regression.” Springer Science & Business Media, 2006.
[3] Schmidt-Hieber, Johannes. “Nonparametric regression using deep neural networks with ReLU activation function.” arXiv preprint arXiv:1708.06633 (2017).
[4] Ham, Ji Hun, Daniel D. Lee, and Lawrence K. Saul. “Learning high dimensional correspondences from low dimensional manifolds.” (2003).
[5] Tenenbaum, Joshua B., Vin De Silva, and John C. Langford. “A global geometric framework for nonlinear dimensionality reduction.” Science 290.5500 (2000): 2319-2323.
[6] Chen, Minshuo, Jiang, Haoming, Liao, Wenjing, and Zhao, Tuo. “Efficient approximation of deep relu networks for functions on low dimensional manifolds.” arXiv preprint arXiv:1908.01842 (2019).
[7] Glorot, Xavier, Antoine Bordes, and Yoshua Bengio. “Deep sparse rectifier neural networks.” International conference on artificial intelligence and statistics. 2011.
[8] Cybenko, George. “Approximation by superpositions of a sigmoidal function.” Mathematics of control, signals and systems 2.4 (1989): 303-314.
[9] Yarotsky, Dmitry. “Error bounds for approximations with deep ReLU networks.” Neural Networks 94 (2017): 103-114.
[10] Tan, Mingxing, and Quoc V. Le. “EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks.” International conference on machine learning. 2019.
