
“Can machines categorize new things by learning how to group similar things together?”
The following describes work by Yen-Chang Hsu, Zhaoyang Lv, and Zsolt Kira, which will be presented at the 2018 International Conference on Learning Representations (ICLR) in Vancouver. Read the paper here.
Clustering is the task of partitioning data into groups, so that objects in a cluster are similar in some way. It sounds easy, and we human usually do it effortlessly. However, it can be an ambiguous task. Let’s consider grouping the following four test images into two clusters:
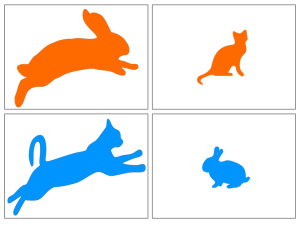
Was it obvious how to do it? Here is a hint: There are four possible criteria: color, pose, species, and size, and the general task of grouping these items does not specify which to use.
The multiple ways to do this probably confused you. Now try to imagine that you are in an exam and you have the following example clustering given to you first. What criteria would you choose for the test images now?
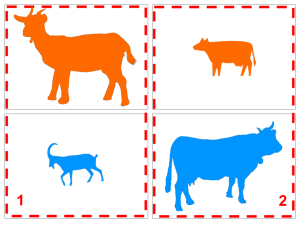
The test becomes much easier when context is given and you can practice, allowing you to learn the criteria from the examples and then apply the rules to group new images. The ICLR 2018 paper “Learning to cluster in order to transfer across domains and tasks” (L2C) describes how to mimic this process using neural networks.
Why does this method of learning to cluster matter? It is a way to use prior knowledge to discover new things. We rely on this ability to abstract things that are seen, in order to reason about new things without being overwhelmed by the innumerable details of the physical world. Therefore, a similar capability to “learn how to cluster” would be useful when building an artificial intelligence (A.I.) system as it would allow it to reason about unseen things (moving away from being able to reason about only things that it was already trained on).
Let’s look again at the steps necessary to solve the exam question:
- Learn the concepts necessary to group things from example clustering.
- Transfer the concepts to cluster new test images.
The L2C paper adopts the same two steps, all using deep neural networks. In the following sections, we will dive a little bit into the technical parts of the article.
Learning the concepts for categorization
The most common way to do categorization is to formulate it as a supervised classification task. The classifiers are learned from labeled examples and applied to the test images. In such a setting, the categories in examples and tests must be the same although they may look different across different datasets. This is known as transfer learning across domains (i.e., the same set of categories have to be classified in different datasets). However, knowledge in the learned classifiers is bound to specific categories and thus is not suitable for discovering new knowledge. The more general setting is transfer learning across tasks, which considers different sets of categories in different datasets, and is the focus of discussion here.
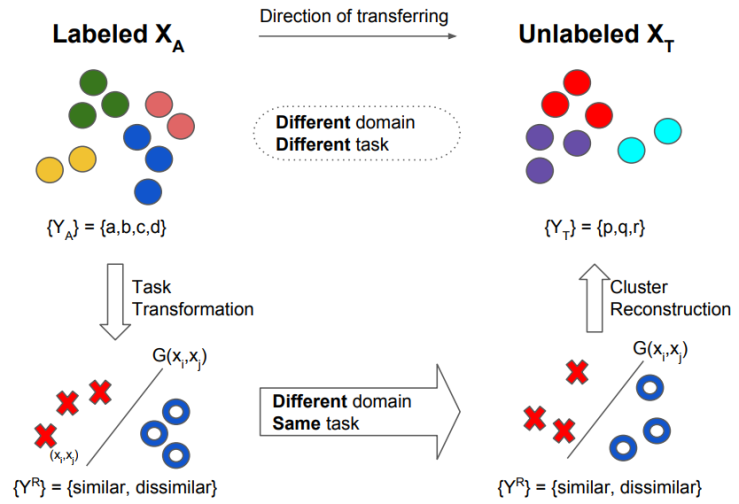
What kind of knowledge representation can be transferred across tasks? The L2C paper presents an idea that first converts the categorical knowledge “{Image:Label}” to pairwise relationships “{(Image A, Image B): Similarity Label}”, where similarity means whether the labels of Image A and B are the same or not. The pairwise relationship is category-agnostic; therefore it can be naturally transferred to a new dataset of unseen categories and used to group them.
How can we learn the pairwise relationships? One way is to learn a function to predict whether a pair of images belongs to the same category (similar) or not (dissimilar). The function can be a neural network, an SVM, or any other classifier. The learned function contains the knowledge that we want to carry to another dataset. Here is the roadmap for using it:
- Learn the similarity prediction function with examples.
- Get the predictions by applying the similarity prediction function on test images.
- Reconstruct the clusters of test images with the predictions in step 2.
The following diagram summarizes the process. The knowledge is transferred in a counter-clock direction. Here, XA is the labeled examples and XT is the test images. The notation {YA} and {YT} represent the categories in datasets, while the G is the pairwise similarity prediction function.
Reconstructing the clusters
With the pairwise similarity predictions, we now have more clues of how images should be grouped together. However, there are a few potential issues. First, there might be many mistakes in the similarity predictions (since they are transferred across different datasets). How badly could it affect the clustering results? Many clustering algorithms are vulnerable to noise. The L2C paper proposes to use a neural network-based constrained clustering, which shows great robustness against the noisy similarity predictions. The designed network can directly output the probability of how an image should be assigned to a particular cluster. The neural network is trained to make a pair of cluster distributions look similar if the images are predicted to be a similar pair, while making the distributions dissimilar otherwise. A figure from the previous ICLR workshop paper has an illustration of how this clustering network works:

Discovering new categories by grouping things
Once the neural network is trained to minimize the conflicts between the predicted similarity and the predicted cluster distribution, we can feed new images into the network to obtain the final cluster assignment. How well does this method perform for discovering new categories? A figure from the report “Deep Image Category Discovery using a Transferred Similarity Function” has a visualization of the results. In that work, the similarity prediction function is learned from about 900 categories in the ImageNet dataset. The clustering is performed on a randomly held-out 10 categories. The images are put close to each other if their chance of being in the same cluster is high. Look at the pictures of birds, the neural network figured out how to define species! In the ICLR 2018 paper, it demonstrates state of art results across many different datasets, comparing to a number of clustering algorithms. It also shows that the method helps the first problem we discussed (domain shift) where the object categories are the same but look different across datasets, even though it did not directly target that problem.

Conclusion
“Learning to Cluster” is a data-driven clustering strategy. It learns the meta-knowledge necessary for defining categories from data, and then uses this knowledge to discover new ones. In the era where unlabeled data are exponentially increasing, transferring knowledge from labeled data is crucial for data mining and many other applications. We hope that the introduced line of work provides you a new perspective that redefines the classical idea of clustering.
Acknowledgments and Further Reading
This work was supported by the National Science Foundation and National Robotics Initiative (grant # IIS-1426998). Further details and experiments are available at https://arxiv.org/abs/1711.10125.
[Post written by Yen-Chang Hsu and Zsolt Kira]

Impressive! I’m dealing with similar problem in dialogue system.
Your work inspire me a lot. Thank you so much.
LikeLike
[…] Learning to ClusterIn “Research” […]
LikeLike