
(Joint work by Abhishek Das, Samyak Datta, Georgia Gkioxari, Stefan Lee, Devi Parikh, and Dhruv Batra)
Humans have a rich, intuitive understanding of the physical world around them, and are able to effectively communicate this understanding using language. To this end, while today’s artificial agents are (surprisingly) good at answering natural language questions grounded in an image, they suffer from a crucial shortcoming — they cannot actively control the pixels coming their way (what if I can’t answer a question from my current view?) or interact with the environment. This is a critical next step in the move towards physical robots that can learn via interaction in-the-wild and communicate in natural language. How do we build artificial agents with such capabilities?
In this post, I’ll talk about recent work from our lab on one instantiation of this goal of combining active perception, language grounding and action execution — Embodied Question Answering (EmbodiedQA, paper available here). In EmbodiedQA, an agent is spawned at a random location in an environment (a house or building) and is asked a question (“What color is the car?”). The agent perceives its environment through first-person vision (a single RGB camera) and can perform a few atomic actions: move-forward, turn-right and turn-left. The objective of the agent is to intelligently navigate the environment and gather visual information necessary to answer the question (“orange”). This will be our running example throughout (illustrated below).
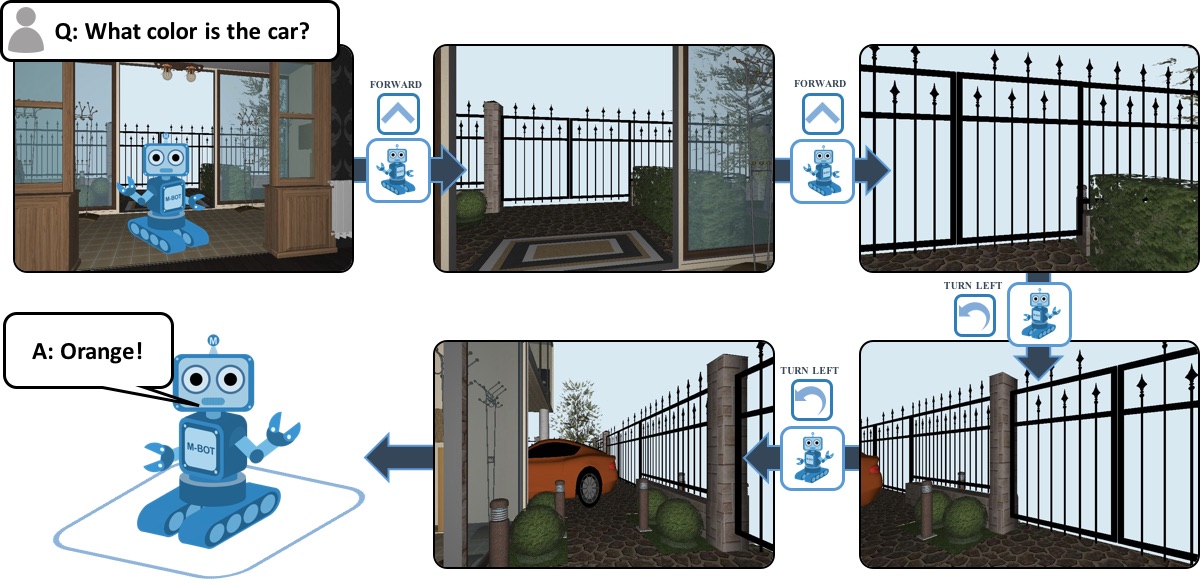
EmbodiedQA combines several well-studied AI problems. Active perception: the agent may be spawned anywhere in the environment and may not immediately ‘see’ the pixels containing the answer to the visual question (‘car’ may not be visible). So the agent must move, thus controlling the pixels that come its way. Common sense: the agent is not provided a labeled map of the environment, thus it must learn common sense information (where are ‘cars’ typically found in a house?) and formulate a sequence of actions based on this knowledge (i.e. navigate to the garage to find the car). Language grounding: our agent grounds a visual question not only into pixels but also into a sequence of actions (‘garage’ is an indication to navigate towards the house exterior where cars are usually parked). Moreover, this form of grounding is essential to succeed at the task — our questions are programmatically constructed to be balanced in their distribution of answers (the ‘car’ is equally likely to be red, orange, black, etc). Thus, without performing grounding and navigation, the agent cannot succeed.
EQA v1 dataset
We instantiate EmbodiedQA in House3D, recent work out of Facebook AI Research on converting 3D indoor scenes from the SUNCG dataset into rich, interactive environments. Questions for this task are generated programmatically using functional forms, in a manner similar to CLEVR, to allow for a fine-grained compositional test of the performance of the answering system. For example:

These functional forms get executed on the environment’s annotations to generate the answer, and so while we do have the flexibility to automatically generate tens of thousands of questions and associated answers, we carefully control for the entropy of answer distribution, so that models can’t pick up on trivial biases to predict the answer.
Overall, we have the following question types:
- location (e.g. “What room is the piano located in?”),
- color (e.g. “What color is the car?”),
- place preposition (e.g. “What is on the table in the living room?”),
- existence (e.g. “Is there a television in the living room?”),
- logical (e.g. “Is there a table and a lamp in the office?”),
- counting objects (e.g. “How many chairs in the living room?”),
- counting rooms (e.g. “How many bathrooms in the house?”), and
- distance (e.g. “Is the microwave closer to the refrigerator than to the sink in the kitchen?”).
For EQA v1, we restrict ourselves to location, color and place preposition questions across ~750 environments. Associated with each question in each environment, we have an oracle shortest path navigation from a random spawn location to the target object the question asks about. Our environment splits have no overlap from train to val to test, so we strictly check for generalization to novel environments.
Hierarchical Recurrent Network
From a modeling perspective, EmbodiedQA can be decomposed into goal-driven navigation and question answering. Navigation is essentially a multi-step sequence prediction problem, so a sequence-to-sequence (Sutskever et al.) approach from question to navigation is a natural first step. However, due to the long-range time dependencies (ranging up to 50-100 steps of navigation), these ‘flat’ recurrent policy networks often forget their goals and get stuck (at corners, walls, etc).
Instead, a hierarchical policy alleviates some of these issues and is better equipped to plan over long-range time sequences. Concretely, our model is a hierarchical recurrent neural network, that separates navigation decisions between a planner and a controller. The planner is modeled as an LSTM, and takes as input an image feature, previous action and the question, and predicts which action to perform. Control is then passed on to the controller, modeled as a feedforward multi-layer perceptron, which takes the planner’s hidden state, image feature and the action sampled by the planner, and predicts how many time-steps to continue making the same action for before handing back control to the planner. This separation ensures that the planner operates over much shorter time sequences (15-20 steps), and is able to plan better.
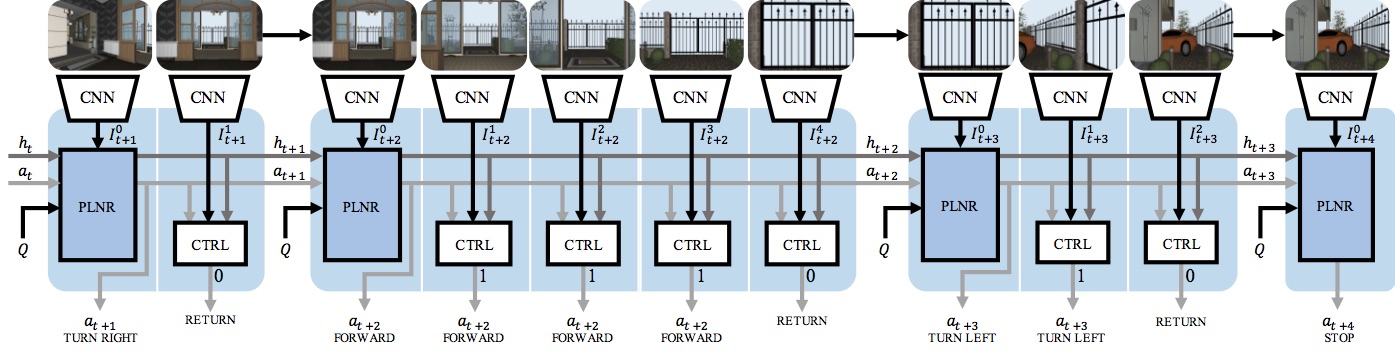
The question answering module looks at the last 5 images from agent navigation, computes attention over them based on image-question relevance, combines the attention-pooled image features with question encoding and outputs a probability distribution over the space of answers.
Since we’re operating in a virtual environment, we have access to vast amounts of auxiliary supervisory signals to pretrain our models. Our visual module, which processes images, is a convolutional neural network that is pretrained under a multi-task framework for autoencoding, semantic segmentation and depth estimation. We use this pretrained image encoder as a feature extractor for navigation and question answering. The navigation module is pretrained on shortest path navigations from a random spawn location to target object for each question and the question answering module is pretrained to predict the answer from the last 5 image observations of shortest path navigation.
While these individual modules perform well independently, they still aren’t robust to dealing with each other, and errors tend to cascade when naively combined (poor navigation —> poor question answering). Thus, we plug these individual components together and fine-tune the navigation module for downstream task performance (based on the answering module’s prediction). Since this involves sequential sampling (for navigation) as an intermediate step, we use policy gradients (REINFORCE in particular), with the answering reward as 5 (when the agent chooses to stop and answers correctly), 0 otherwise, and intermediate navigational rewards as 0.005 times the change in distance to target. And that’s it! The model performs quite reasonably compared to a vanilla LSTM baseline, and more crucially, all of it is learned end-to-end without any explicit mapping and planning components, which is quite remarkable (see video).
We evaluate intermediate navigational performance as well as question answering accuracy via a host of metrics — distance to target object at termination, change in distance to target from initial to final position, closest distance to target, etc. and mean rank of the ground truth answer in the answer probabilities predicted by the model. And our simple approach performs favorably compared to baselines.
We also benchmark human performance by hooking up the House3D virtual environment to Amazon Mechanical Turk (AMT), allowing subjects to remotely operate the agent and perform the EmbodiedQA task. Humans (obviously) perform much better than our artificial agents. 🙂
To summarize, in this initial effort, we introduced the EmbodiedQA task, a dataset instantiated in the House3D environment, and a simple hierarchical recurrent network for navigation. We believe EmbodiedQA combines language understanding, active vision and actions in a challenging, new task. Our dataset, code for question generation, training models, and AMT interface will be publicly available. Studying generalization to real environments, making better use of the inherent 3D structure of the visual world, and baking in explicit mapping capabilities in the model are exciting future directions.
This post is based on the following paper:
Embodied Question Answering.
Abhishek Das, Samyak Datta, Georgia Gkioxari, Stefan Lee, Devi Parikh, Dhruv Batra.
CVPR 2018. (pdf)

Is the dataset available yet?
LikeLike
Hey, yes, the dataset is available at embodiedqa.org/data.
LikeLike