
By Yuval Pinter
Imagine you’re building a boat, starting from a heap of parts. With each new board or screw, you make sure that it fits the adjacent parts, and that the material type is suitable for the section of the boat it’s in. But there are also bigger concerns to consider – is the new part changing the structure of the boat as a whole? Will it remain stable, or will it start rocking? Maybe there are other places where this part fits that would make more sense, but it’s not even where you’re currently looking.

In Natural Language Processing (NLP), some aspects of linguistic structure are like a boat. Specifically, the structure known as a semantic graph helps a wide variety of AI systems represent knowledge about the world by explicitly connecting linguistic concepts using different relations to create a massive network where each dictionary entry has its place. A few examples, from the manually-crafted semantic graph WordNet, include:
- cat is a mammal.
- wheel is a part of a vehicle.
- Rome is an instance of national capital.
- musical is derived from music.
- language is like a boat. (Just kidding about this one.)
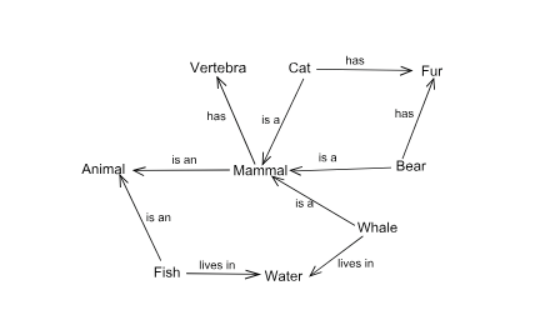
These individual connections are the alluded “adjacent fits” from the boat metaphor. There are tens of thousands of parts in WordNet, and hundreds of thousands of these connections, of about a dozen types. But there is also a wider perspective to look through – that of the overall structure of the graph. For example, consider the “is a” relation, known in the trade as hypernymy. If we were to create hypernym connections between cat and mammal, then mammal and animal, then animal and cat, we would be building a structure that represents an impossible fact, that cat is both more general and more specific than animal. Other ways of rocking the boat can be the inclusion of improbable facts. For example, that cat is both mammal and vehicle. These mistakes can be averted if we know that the hypernym graph cannot contain directed cycles (for the first case) and that it should have as few concepts with multiple outgoing edges as possible (for the second).
In our paper, Predicting Semantic Relations using Global Graph Properties, we look into how this type of graph-level information (which we call global) can help find meaningful relations in a semantic graph. This task is typically done using adjacency-based techniques (which we call local), most of which are based on word embeddings.
First, we train a strong local model on English WordNet on the task of predicting a hidden side in a relation edge when the other side and the relation type are known. For example, the model is asked “which word is derived from music?” and is expected to know the answer, musical. In practice, what the model does is compute a score based on a neural network which composes representations (embeddings) for musical and derived-from with every concept in the dictionary, and ranks them based on this score. The training objective (and testing metric) is to rank music as high as possible.
Once this model is trained, we use its scoring ability to train a second component which is based on the global features of the graph. Each feature is a count of some graph property:
- How many concepts are hypernyms of other concepts?
- How many concepts are both a hypernym of something and a part of something?
- How many concept pairs are connected both via a derivation relation and a common domain topic?
And so on, totaling about 1,000 features. Using a training regime we call Max-Margin Markov Graph Models, or M3GM, we learn weights for each feature and use them to score the graph each time a new relation is suggested. In test time, we use the global model to re-rank the top 100 suggestions from the local model, and as our experiment shows, gain major improvements over the basic model.
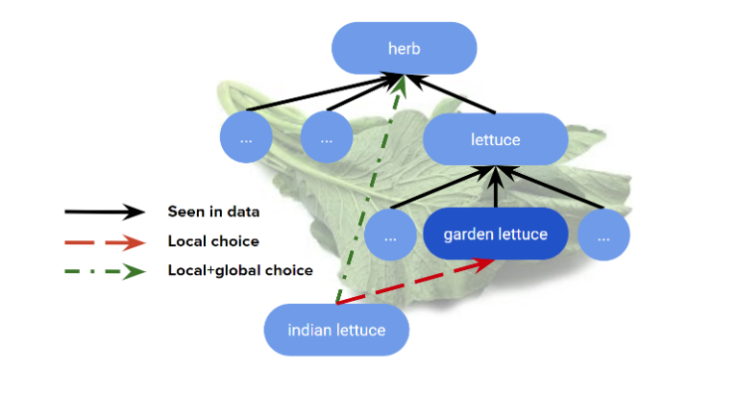
Digging in, we see how specific improvements are motivated in facts we know (or suspected) about linguistic structure. For example, our global model learned that fewer hypernym concepts are better – we don’t want an excess of general concepts that spread the graph too wide or too deep. When the model is asked what the hypernym of Indian lettuce is, the local component wants to choose garden lettuce, but the global part rejects this new hypernym and selects (correctly) herb, an existing hypernym, in its place.
You can find details of our model, and discussions of other ways the different weights correspond to insights about the structure of language, in the paper. Our code is available here.
====
Yuval Pinter and Jacob Eisenstein. Predicting Semantic Relations using Global Graph Properties. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), 2018.

Reblogged this on מקפים לוהטים and commented:
My upcoming talk at EMNLP
LikeLike